Hi guys,
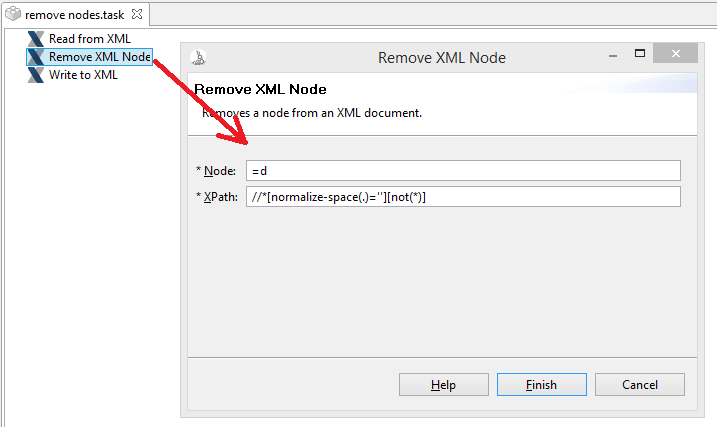
I have an XML document I’m filling out with data from excel, however any elements without a value at the end I need to remove from the XML doc. I can delete empty elements using the xpath “//<myelement>//[not()]” in the remove XML node operation and that works fine on anything like <element></element> or <element/>. However, when I run this it only deletes the node, not the whitespace too, so for example, if I have:
<element>
<element2/>
</element>
and I use that xpath to delete xml nodes it leaves me with
<element>
</element>
with whitespace in between <element> and </element>. If I try and run the same operation, I would expect it to now delete the <element> node (as that is now an empty element), however, that doesn’t work as I think it’s now classed not as an empty element, but as one with the whitespace as it’s value…
Is there a way I can delete an element, after deleting an element in between it?