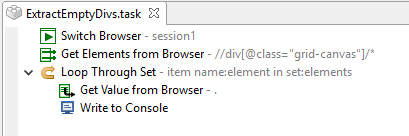
We are reading data from a webpage using
–Get Value from Browser (which is a grid of data)
XPath: //div[@class=“grid-canvas”]
example html in webpage
< div class=“grid-canvas”>
< div class=“slick-cell l6 r6”>SENT< /div>
< div class=“slick-cell l7 r7”>FILES< /div>
< div class=“slick-cell l8 r8”>12345< /div>
< div class=“slick-cell l9 r9”> < /div>
< div class=“slick-cell l0 r10”>< /div>
< div class=“slick-cell l11 r11”>14/10/2016< /div>
< /div>
It picks up the values SENT, FILES 12345 & 14/10/2016
But it will not pick up fields r9 or r10
r9 contains a single space
r10 is empty.
Is there any way we can extract this information, or at least the single space?
Thanks
Darren.